Support 24/7: +48 61 646 07 77
20 października 2025 r. problemy w regionie AWS us‑east‑1 wywołały falę zakłóceń w aplikacjach konsumenckich, bankowości, serwisach rządowych i nawet w części usług Amazona. Downdetector zebrał ponad 17 milionów zgłoszeń od użytkowników z 60+ krajów. To pokazuje, jak bardzo internet jest dziś skupiony wokół kilku wspólnych „węzłów”.
Co się wydarzyło – w skrócie:
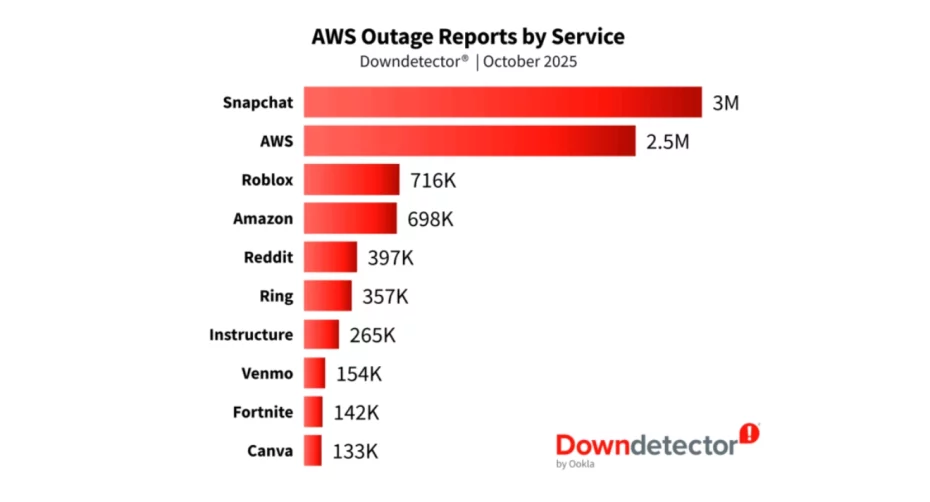
Najwięcej zgłoszeń pochodziło z USA (6,3 mln) i Wielkiej Brytanii (1,5 mln), dalej Niemcy, Holandia, Brazylia.

Z usług najmocniej odczuły to m.in.: Snapchat, AWS (panele i API), Roblox, Amazon Retail, Reddit, Ring.
Sektorowo widać wpływ na: social/gaming, bankowość (np. brytyjskie banki), administrację (np. HMRC), smart home (Ring, Alexa), edukację i narzędzia pracy.
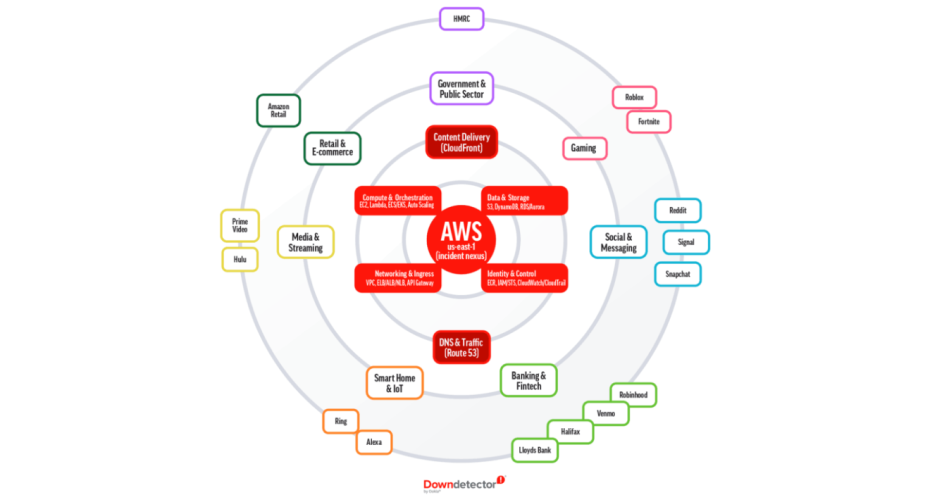
Koncentracja: us‑east‑1 to najstarszy i jeden z najbardziej obciążonych regionów AWS. Wiele „globalnych” aplikacji trzyma tam krytyczne elementy: logowanie, dane użytkowników, metadane, kolejki zleceń.
Wspólne zależności: jeśli przestaje działać podstawowa usługa, z której korzystają setki innych (np. baza danych albo mechanizm nadawania uprawnień), efekt rozlewa się szeroko.
Dostęp administracyjny: część zespołów miała trudność z zalogowaniem się do panelu AWS — to spowalnia naprawę, bo nie zawsze da się szybko przełączyć ruch lub uruchomić zapasowy wariant.
Awaria w jednym regionie chmurowym potrafi rozlać się na wiele krajów i branż. Celem nie jest „zero awarii”, tylko takie projektowanie i operowanie systemem, by skutki były ograniczone, a powrót do normalnego działania szybki i przewidywalny. Poniżej przykładowy plan działań, który sprawdzi się w sklepach internetowych, bankowości, administracji, mediach i wszędzie tam, gdzie każda minuta przestoju liczy się podwójnie.
Uruchom drugi region dla kluczowych funkcji (logowanie/SSO, wyszukiwarka, koszyk/zamówienie, płatności, panel klienta).
Jeśli utrzymywanie dwóch w pełni działających kopii systemu jednocześnie (w dwóch regionach) jest dziś za drogie, przygotuj w drugim regionie lekki zapas: minimalną wersję środowiska z aktualnymi danymi i gotową konfiguracją, którą automatycznie podniesiesz i powiększysz, gdy podstawowy region padnie.
Testuj przełączenie co najmniej raz w miesiącu i mierz czasy (wykrycie, decyzja, pełny powrót).
Na co dzień aplikacja działa w regionie Europa‑Zachód. W Europie‑Północ masz replikę bazy i przygotowane szablony serwerów/aplikacji. Gdy pierwszy region ma awarię, skrypty włączają aplikację w drugim regionie i kierują tam ruch klientów.
Wyłącz dodatki. Jednym kliknięciem/automatem odetnij rzeczy „miłe, ale zbędne”: duże galerie, rekomendacje, eksporty, mniej ważne integracje.
Zostaw rdzeń usługi. Muszą działać: logowanie, wyszukiwanie, koszyk i płatność / zlecenie przelewu / złożenie wniosku / zakup biletu.
Uspokój ponowne próby. Ustal limit prób i krótkie przerwy między nimi, żeby nie „zapchać” bazy i integracji.
Miej kopię danych do logowania (sesje, uprawnienia) w co najmniej dwóch miejscach.
Zabezpiecz awaryjne wejście dla administratorów: specjalne konto, drugi sposób logowania, kanał poza główną chmurą.
Pilnuj adresów (DNS): krótkie czasy odświeżania i gotowa procedura szybkiego przekierowania ruchu.
Zbieraj sygnały w jednym miejscu: metryki aplikacji, infrastruktury + informacje z zewnątrz (np. raporty o awariach).
Automatyczne decyzje przy alarmach: przełącz na drugi region, wyłącz zbędny moduł, ustaw tryb tylko‑odczyt.
Po incydencie krótka analiza: co poprawiamy, kto za to odpowiada, do kiedy (post‑mortem).
Rób ćwiczenia: „nie działa logowanie”, „padła baza”, „problem z adresami”, „płatności niedostępne”.
Sprawdź doświadczenie użytkownika i wsparcia: co widzi klient, jak odpowiada helpdesk.
Aktualizuj instrukcje i skracaj decyzje: kto przełącza, czym, w jakiej kolejności.
Najbardziej krytyczne rzeczy (np. płatności, DNS/CDN) możesz zdublować u drugiego dostawcy.
Zwykle wystarczy dobrze zaprojektowane dwa regiony u jednego dostawcy — mniej złożoności, lepszy koszt/efekt.
Gotowe komunikaty na status page i w aplikacji: co działa, co nie, kiedy kolejna aktualizacja.
Miej próg komunikacji o winie dostawcy, żeby ograniczyć lawinę ticketów i utrzymać zaufanie.
Mapa zależności: kto dostarcza DNS, płatności, CDN, pocztę, analitykę, logowanie.
Ustal SLA i plany awaryjne z kluczowymi partnerami i sprawdzaj je w testach.
W sektorach regulowanych wdrażaj praktyki DORA/NIS2: testy odporności, raportowanie incydentów, przeglądy dostawców.
Architektura odporna na awarie: projektujemy drugi region dla kluczowych funkcji (logowanie, koszyk/płatność, podstawowe API) i weryfikujemy go testem przełączenia.
Tryb awaryjny sprzedaży/usługi: konfigurujemy proste przełączniki, które w razie kłopotów zostawiają rdzeń działania, a „dodatki” wyłączają automatycznie.
Monitoring i szybkie decyzje: łączymy metryki aplikacji/infrastruktury z sygnałami zewnętrznymi; ustawiamy progi, po których system sam przełącza region lub ogranicza ruch.
Runbooki i komunikacja: dostarczamy krótkie instrukcje dla zespołu i gotowe komunikaty dla status page / aplikacji.
Zgodność i dostawcy: porządkujemy mapę zależności (DNS, CDN, płatności, logowanie), SLA i podstawowe wymagania DORA/NIS2.
Operacja 24/7 (SDO): nasz Service Desk ma żywy dyżur i eskaluje do inżynierów, żeby skracać czas reakcji.
Awaria jednego regionu chmury potrafi zatrzymać wiele usług naraz i to w różnych krajach. Wniosek jest dość okrutny – nie da się zagwarantować „zera awarii”, ale da się sprawić, by kłopot był krótszy, tańszy i mniej bolesny dla klientów. Co może pomóc? Przygotowany drugi region dla krytycznych funkcji, prosty tryb awaryjny (zostawiamy tylko to, po co klient przyszedł), jasne progi automatycznych decyzji oraz krótkie, zrozumiałe instrukcje i komunikaty. To nie są dodatki – to element podstawowej higieny działania.
Jeśli chcesz sprawdzić, jak to wygląda u Ciebie, zrobimy szybki przegląd i wskażemy 2‑3 konkretne kroki, które najszybciej podniosą odporność – bez wielkiej rewolucji w systemie.





















































































![Bezpieczeństwo środowisk testowych [krótki poradnik dla DevOps/SysOps]](https://centuria.pl/wp-content/uploads/2022/09/07-12-bezpieczenstwo-srodowisk-424x228.jpg)















