Support 24/7: +48 61 646 07 77
18 listopada 2025 r. internet na kilka godzin wyraźnie zwolnił. Tysiące serwisów – w tym X (Twitter), ChatGPT, Spotify, serwisy bankowe i sklepy internetowe – zaczęły masowo zwracać błędy 5xx. Wspólnym mianownikiem był jeden dostawca: Cloudflare, który obsługuje znaczącą część globalnego ruchu HTTP. Cloudflare jeszcze tego samego dnia przyznał, że nie był to cyberatak, tylko… ich własny błąd konfiguracyjny w systemie Bot Management. W tym tekście przechodzimy po ludzku przez techniczne szczegóły awarii i – ważniejsze – wyciągamy wnioski dla CTO, osób odpowiedzialnych za infrastrukturę i właścicieli biznesów e‑commerce.
Oś czasu (UTC):
Cloudflare bardzo szczegółowo opisał, co poszło nie tak. W wersji „dla ludzi” wyglądało to tak:
System Bot Management używa pliku z listą „cech” (feature file), które zasilają model ML oceniający, czy dane żądanie HTTP jest botem.
Ten plik jest generowany co kilka minut przez zapytanie do klastra ClickHouse.
Wprowadzono zmianę uprawnień w bazie, dzięki której użytkownicy mieli jawny dostęp do dodatkowej przestrzeni r0 z tabelami bazowymi.
„Niewinne” zapytanie:
zaczęło zwracać duplikaty kolumn – z default i z r0. Plik cech nagle urósł ponad dwukrotnie.
Moduł proxy (nowa generacja FL2) miał twardy limit – maks. 200 cech. W praktyce używano ~60, więc nikt nie zakładał, że limit będzie realnym problemem.
Kiedy na serwer trafił zbyt duży plik, kod w Rustcie zrobił unwrap() na wyniku z błędem – i wątek roboczy w serwerze proxy po prostu się wywalił („panic”).
Efekt dla użytkownika: 500 Internal Server Error.
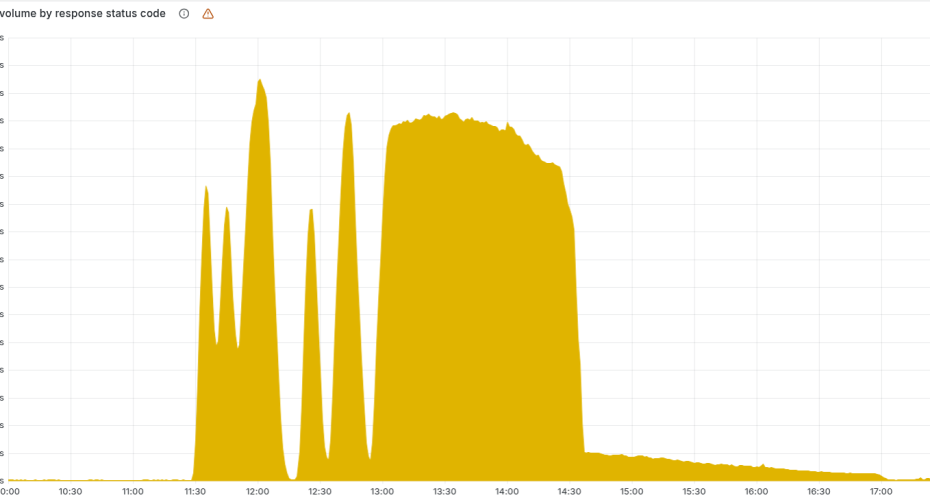
Ponieważ plik był generowany cyklicznie, a zmiana uprawnień była wdrażana stopniowo, sieć przez pewien czas „klapowała”: raz działał poprawny plik, raz wadliwy. To tłumaczy sinusoidę na wykresach 5xx i dostępności.
Dopiero gdy wszystkie nody bazy generowały już wadliwy plik, awaria stała się stabilna… w zły sposób.
Pierwsza intuicja wielu osób (również wewnątrz Cloudflare) była taka: „to musi być ogromny atak DDoS”. W tle jest trwająca od miesięcy fala bardzo dużych ataków z użyciem botnetu Aisuru, więc podejrzenie nie było oderwane od rzeczywistości.
Kilka godzin później firma potwierdziła: żadnego ataku. Po prostu zły interplay między:
zmianą uprawnień w bazie,
zapytaniem, które zakładało pewien kształt odpowiedzi,
brakiem walidacji pliku konfiguracyjnego,
twardym limitem w proxy i fatalnym obsłużeniem błędu (unwrap).
Z perspektywy użytkownika sklepu internetowego nie ma to jednak znaczenia, czy powodem był SQL, DDoS czy kabel pod oceanem. „Nie działa” = nie kupuję.
I to jest pierwszy ważny wniosek dla zarządów: przyczyna techniczna jest ciekawa dla inżynierów, ale prawdziwym tematem jest odporność biznesu na awarie, na które nie mamy wpływu.

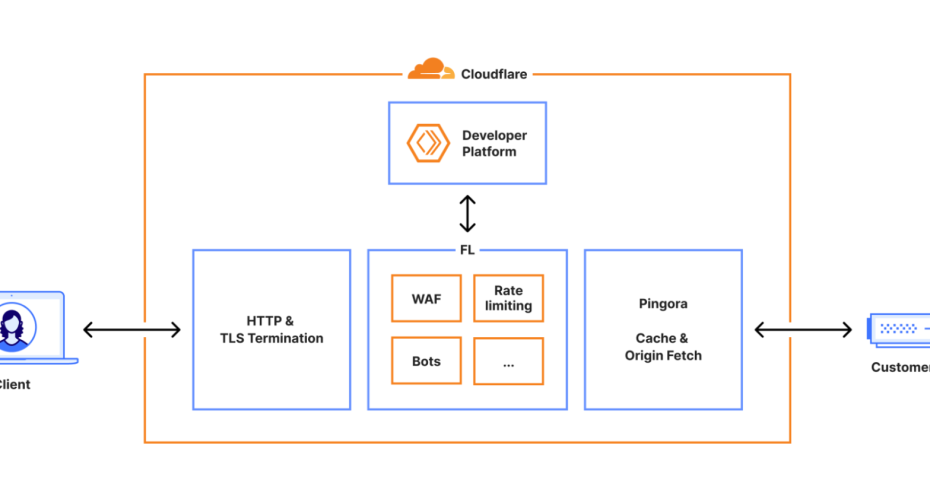
Cloudflare to:
CDN / reverse proxy,
ochrona DDoS, WAF, Bot Management,
DNS, Turnstile (zamiennik CAPTCHA),
narzędzia dla developerów itd.
W praktyce – dla wielu sklepów to brama do internetu. Gdy ona pada, nie ma znaczenia, że serwery aplikacji i baz danych są zdrowe i dostępne.
Szacunki mówią o nawet 2,6 mld użytkowników dotkniętych skutkami awarii i milionach serwisów, które przestały działać poprawnie.
Jeżeli Twój sklep:
używa Cloudflare jako frontu HTTP,
trzyma DNS w Cloudflare,
polega na ich WAF / Bot Management / Turnstile,
to w takiej sytuacji masz single point of failure poza własną infrastrukturą. I żadna umowa SLA nie sprawi, że ta zależność magicznie zniknie.
Ta awaria jest podręcznikowym przykładem kilku klasycznych anty‑wzorców.
Cloudflare bardzo uczciwie przyznaje: plik generowany wewnątrz ich systemu nie przeszedł takiej walidacji, jak dane od użytkownika. Nie było twardych checków:
maksymalny rozmiar pliku,
maksymalna liczba cech,
mechanizm „gdy coś odbiega od normy, wyłączamy nową wersję i wracamy do starej”.
Wnioski dla zespołów:
każdy plik konfiguracyjny (czy to YAML z feature‑flagami, czy JSON z regułami WAF) traktujemy jak nieufny input,
walidacja powinna być niezależna od komponentu, który ten plik konsumuje,
config rollout powinien mieć szybki, automatyczny rollback.
W Cloudflare limit 200 cech miał sens wydajnościowy – prealokacja pamięci. Problemem było to, że jego przekroczenie kończyło się paniką procesu i globalną 500‑ką.
W dobrze zaprojektowanym systemie:
przekroczenie limitu loguje alarm,
nadmiarowe elementy są ignorowane,
system przechodzi w tryb degradowany (np. Bot Management używa tylko znanego podzbioru cech).
Innymi słowy: lepiej działać gorzej niż wcale nie działać.
Wiele organizacji ma rozbudowane procedury dla releasów aplikacji, a jednocześnie dużo luźniejsze podejście do zmian w konfiguracji. Ta awaria pokazuje, że to krótsza droga do globalnego „stop”.
Dobra praktyka:
spójne pipeline’y CI/CD zarówno dla kodu, jak i konfiguracji,
canary rollout i progressive delivery (mały procent ruchu, potem więcej),
pełna observability: korelacja panik/5xx z ostatnimi zmianami w configu.
Błąd w jednym module (Bot Management) nie powinien zabijać całego proxy obsługującego podstawowy ruch HTTP. Tu zawiodło izolowanie modułów i mechanizm „global kill switch” dla funkcji, która zaczyna sprawiać problemy.
Jeśli w e‑commerce:
jedna integracja płatności,
jedna usługa antyfraudowa,
jeden provider CDN / DNS
jest w stanie położyć cały sklep, to masz zbyt duży blast radius pojedynczego komponentu.
Z perspektywy zarządu i właścicieli e‑commerce kluczowe pytania są inne niż „ile cech było w pliku”.
Cloudflare, AWS i inni dostawcy sprzedają dostępność liczona w dziewiątkach po przecinku. Ostatnio mieliśmy globalną awarię AWS, teraz Cloudflare. Nie ma świętych krów. To prowadzi nas do pytania, które dobrze ujął nasz CEO, Maciej Kalkowski na LinkedIn:
Na ile wierzymy w ciągłość działania definiowaną biznesowo w ofertach usług?
I czy gra naprawdę polega na tym, kto da więcej 9 po przecinku powyżej 99 ten wygrywa?
Odpowiedź jest brutalnie prosta: nie kupisz sobie 100% ciągłości jednym SLA. Ciągłość działania to:
architektura (redundancja, multi‑region, multi‑CDN),
procesy (runbooki, procedury przełączeń, testy DR),
ludzie (kto realnie podejmuje decyzje w sytuacji kryzysowej).
Zamiast dyskutować „czy 99,95% to dużo”, policz:
ile wynosi przychód na godzinę w szczycie,
ile kosztuje Cię 2–3 godziny braku sprzedaży + obsługi klienta + wizerunku,
ile kosztuje wdrożenie architektury, która potrafi przełączyć się na inne ścieżki ruchu (np. drugi CDN, alternatywny DNS, tryb tylko‑odczyt).
Dla wielu średnich i dużych sklepów e‑commerce inwestycja w realny Business Continuity zwraca się przy jednej dużej awarii w roku.
Kilka praktycznych kroków, które rekomendujemy naszym klientom po tej awarii:
Mapa zależności – spisz wszystkich zewnętrznych dostawców, przez których przechodzi krytyczny ruch (CDN, DNS, płatności, wyszukiwarka, antyfraud, mailing transakcyjny).
Klasyfikacja – określ, które z nich są „must‑have do sprzedaży”, a które są „nice‑to‑have”.
Alternatywy – zaplanuj co najmniej jedną alternatywną ścieżkę:
drugi CDN lub możliwość „ominięcia” CDN i serwowania bezpośrednio z originu,
backupowy DNS (lub drugi provider),
alternatywny proces płatności (np. prosty przelew BLIK, gdy bramka kartowa leży).
Tryby degradacji – zdefiniuj, jak sklep zachowuje się w trybie kryzysowym:
wyłączenie ciężkich elementów (rekomendacje, filtry, dynamiczne bannery),
uproszczony checkout,
informacja dla klienta na froncie zamiast białej strony.
Ćwiczenia – przynajmniej raz na kwartał „odłącz” jakiegoś dostawcę na środowisku testowym i zobacz, co się realnie dzieje.
To nie są kosmiczne technologie, tylko konsekwentne podejście procesowe – dokładnie ten mindset, który budujemy w Centurii.
W Centurii nie sprzedajemy serwerów czy pojedynczych usług, tylko systemowe podejście do ciągłości biznesu – proces ponad projekt, stabilność zamiast fajerwerków.
Awaria Cloudflare jest kolejnym przypomnieniem, że:
stabilność to nie przypadek, tylko system,
„bezpieczeństwo by design” oznacza również projektowanie na wypadek błędów naszych partnerów,
rola dostawcy infrastruktury nie kończy się na tym, żeby „działały serwery”, ale żeby transakcje były możliwie odporne na zewnętrzne awarie.
Dlatego w projektach e‑commerce:
projektujemy architekturę z założeniem, że każdy element może kiedyś zawieść,
rekomendujemy rozwiązania, które minimalizują blast radius pojedynczej awarii,
budujemy runbooki i procesy, które pomagają zespołom reagować szybko i w sposób przewidywalny.
Globalna awaria AWS, teraz globalna awaria Cloudflare. To nie są marginalne incydenty – to realne koszty dla tysięcy firm na świecie.
Możemy oczywiście dalej porównywać SLA i liczby dziewiątek po przecinku. Ale dużo ważniejsze pytanie brzmi:
Co się stanie z Twoim biznesem, jeśli jutro na kilka godzin „wyłączą” kolejnego dużego dostawcę, z którego korzystasz?
Jeżeli odpowiedź brzmi: „stoimy”, to znaczy, że prawdziwy problem nie leży w Cloudflare, AWS czy innym logo – tylko w architekturze i procesach. I właśnie nad tym – architekturą, procesami i ciągłością transakcji – warto pracować już teraz, gdy internet znowu działa w normalnym trybie.
Źródło informacji: https://blog.cloudflare.com/pl‑pl/18‑november‑2025‑outage/





















































































![Bezpieczeństwo środowisk testowych [krótki poradnik dla DevOps/SysOps]](https://centuria.pl/wp-content/uploads/2022/09/07-12-bezpieczenstwo-srodowisk-424x228.jpg)















